

桔妹导读:滴滴七层接入平台负责滴滴全公司http东西向和南北向流量的接入,其请求峰值qps数百万,日请求量数千亿,接入域名数千个、接入服务数千个、转发规则数万个,其稳定高效的运行对于保障滴滴业务至关重要。本文将主要介绍七层接入平台在服务治理和稳定性建设上的实践,同时也分享其在云原生领域一些探索和规划。
1. 概况
从2014年底诞生至今,滴滴七层接入平台服务规模如下:
- 负责全公司http请求东西向和南北向的流量接入和治理,涉及多个事业部。
- 请求峰值qps数百万,日请求量数千亿,接入域名数千个、接入服务数千个、转发规则数万个。
千亿级的流量转发规模不仅对系统自身的稳定性和性能提出了极大的挑战,业务对接入平台也提出了更高的期望:除了自身稳定性和性能外,平台要进一步赋能和助力业务稳定性和效能的提升,具体体现在:
自身稳定性
可用性99.99%
自身性能
平均转发延时<1ms
稳定性赋能
作为http服务统一的技术底座和稳定性能力规模化重要抓手,输出各种稳定性基础能力赋能到业务稳定性的建设和提升。
效能赋能
挖掘痛点,提高研发/运维/测试全生命周期的效能。
经过5年的持续迭代和演进,滴滴7层接入平台整体架构如下:整体上分为数据面和控制面两部分:
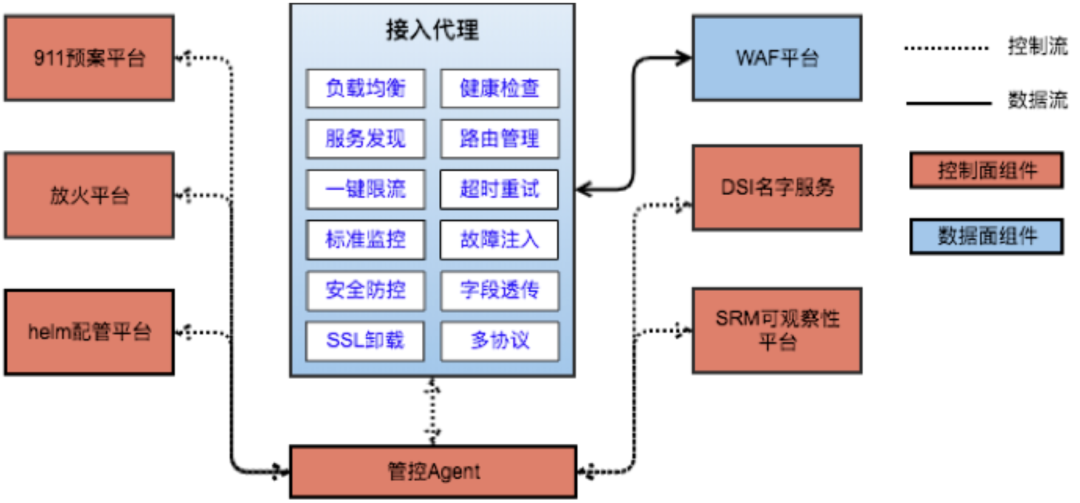
数据面:
基于开源nginx建设,提供高稳定、高性能、多协议、安全的流量接入和服务治理。
控制面:
- 接入和配置变更:自研配置变更平台,用户可以通过配置变更完成域名或服务的接入,并配置丰富的规则和策略。
- 可观察性:请求数据联动滴滴监控体系,提供面向全公司的http服务细粒度和多维度监控以及监控大盘。
- 服务治理:服务治理联动滴滴公司级别911预案平台、放火平台,提供体验统一的预案管理和故障注入操作能力。
- 服务发现:服务发现联动滴滴统一名字服务DSI(Didi Service Information),提供稳定、实时的服务发现能力。
- 安全防控:安全防控联动公司WAF系统,对滴滴全公司应用层安全进行保驾护航。
本文将从以下三个方面进行滴滴七层接入平台的实践和探索介绍:「服务治理能力建设」、「稳定性建设」和「云原生时代接入平台探索」。
2. 服务治理能力建设
我们将从以下几个方面进行服务治理能力介绍:「服务发现」、「预案能力」和「可观察性」。
服务发现
经过调研,社区常用的upstream动态更新方案有4个: 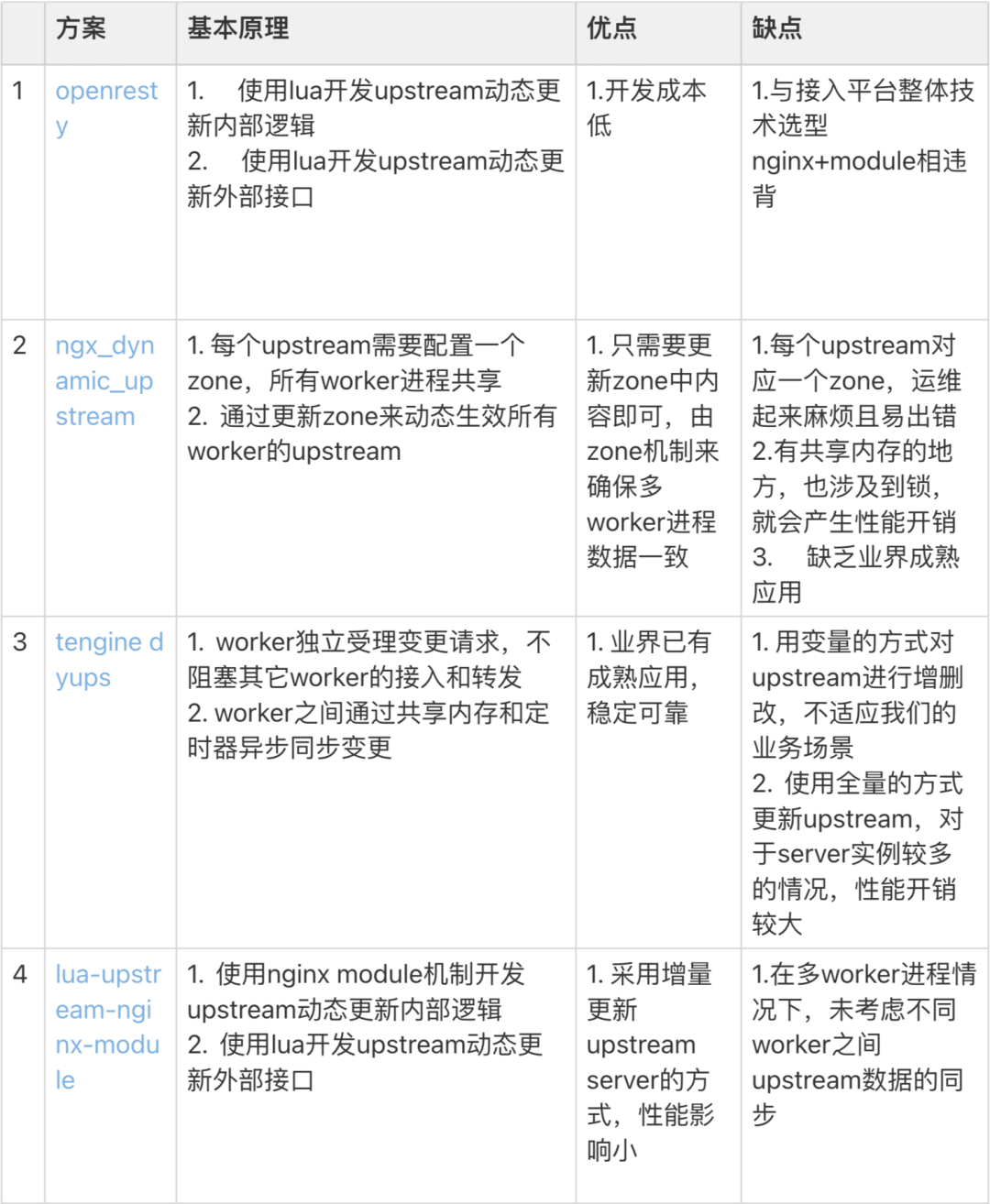
以上方案均不能完全满足我们的需求,参考方案3和方案4,我们重新设计了nginx upstream动态更新模块,兼顾了稳定性、性能和可维护性,支持全公司http服务的服务发现,涉及数千个服务,特点如下:
采用增量更新upstream server机制
提供基于HTTP Restful API的轻量upstream reload接口,实现对upstream的动态变更
完全兼容现有配置方式
对配置进行持久化
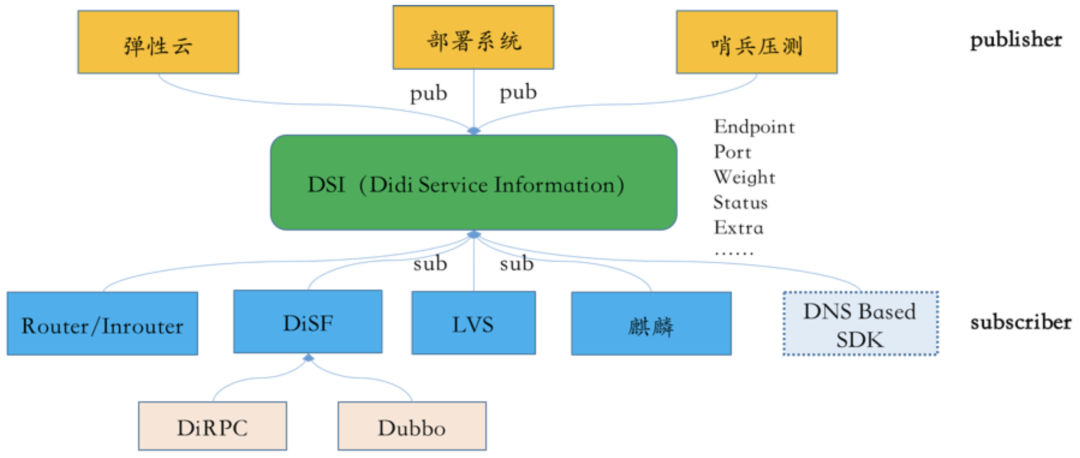
同时通过接入平台的服务发现实践,我们抽象出公司级名字服务DSI(Didi Service Information),DSI通过open api,除了接入平台外,公司服务发现SDK DiSF、四层代理DGW、容器平台、部署系统等系统也已经全部和DSI进行了打通联动,形成了公司基于DSI的统一服务发现体系,同时基于这套服务发现体系,也陆续孵化出一些稳定性工作的平台和能力,比如自动哨兵压测平台进行子系统容量精确评估和预警,比如对业务透明的无损发布机制等。
预案能力
我们基于接入引擎建设了http服务统一的限流、切流、故障注入等底层服务治理能力,并且和公司级911预案平台、放火平台打通联动,提供统一和易用的操作界面供用户使用,具体包括:
- 多维度限流能力、限流阈值自动推荐能力、限流阈值自适应能力,目前已经成为公司稳定性保障的重要抓手
- 多维度切流能力,在滴滴专快异地多活、子系统切流和业务上云灰度中起到了重要的作用
- 基于接口粒度的错误率和延时故障注入能力,已经开始陆续在强弱依赖验证、预案有效性验证等场景中发挥作用。
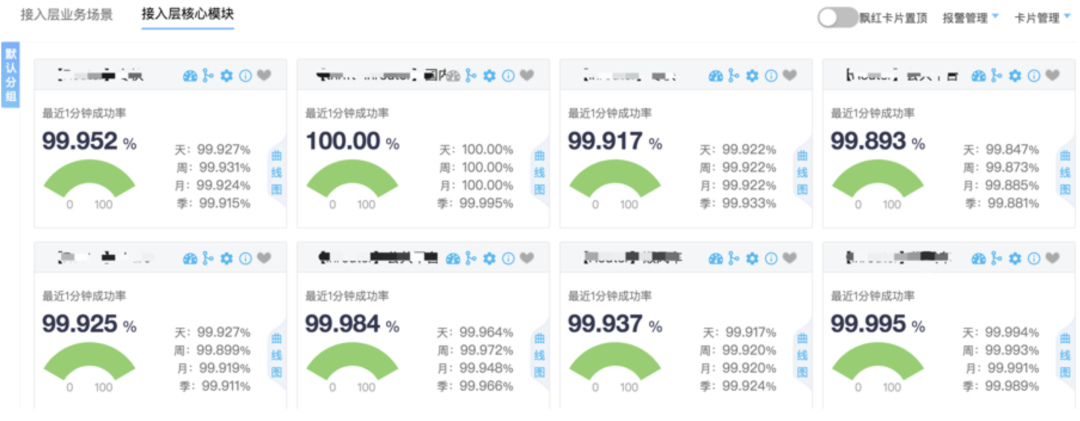
可观察性
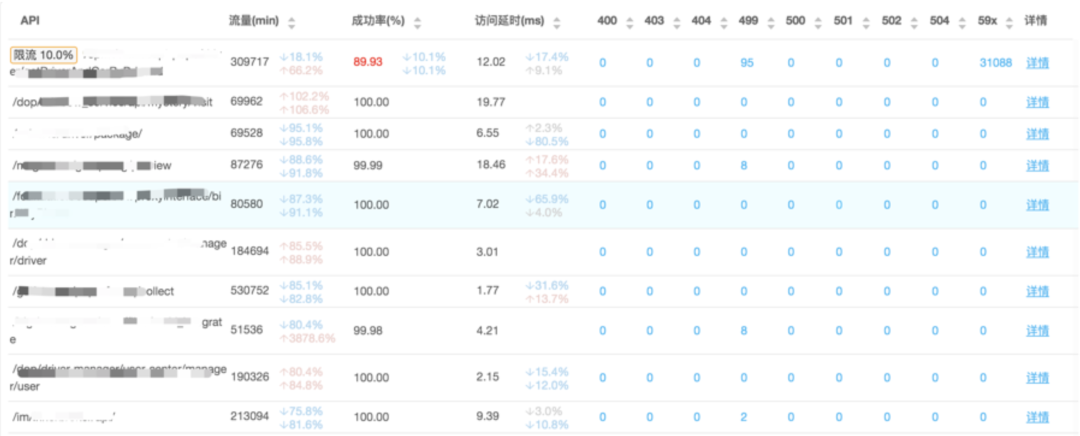
作为流量门户,接入平台通过输出请求标准数据并打通SRM服务可观察性系统,对公司http流量的可观察性起到了重要作用。
3. 稳定性建设
七层接入平台作为公司的超一级服务,对稳定性有着极高的要求,如果接入平台出现稳定性故障,很有可能导致滴滴全平台业务不可用,对公司带来巨大的经济和品牌损失。除了建设稳定性基础能力外,我们还从以下3个方面重点进行七层接入平台的稳定性建设:「归零风险防控」、「接入引擎架构升级」和「配置变更风险防控」。
归零风险防控
我们总结接入平台主要的归零风险为:代码变更异常、容量不足、外网高可用能力欠缺、运维误操作4类,相关应对措施分别为:
代码变更:技术上全部采用公司代码变更风险防控机制的最严标准强制控制,流程上要求变更必须要跨天完成,至少经历早晚两个高峰。
容量不足:制定了快速扩容技术方案,目前正在尝试通过对接入引擎容器化提高弹性伸缩能力。
外网高可用能力:通过httpdns进行流量切换和自建/非自建出口调度能力进行外网止损能力建设。
运维误操作:所有高风险运维操作必须double check和分级、运维操作隔离域功能的应用。
接入引擎升级
最开始我们使用的接入引擎是tengine,版本为2.1.0,发布于2014年12月,tengine基于的nginx版本是1.6.2,2014年4月发布,到2018年,我们陆续发现一些接入引擎的稳定性问题,主要体现在以下3方面:
- 一些隐藏较深的bug不时在接入引擎上出现,修复成本和风险都较高,而最新的nginx已经全部修复。
- 一些新的需求在tengine1.6.2的架构下已经很难继续演进和发展,比如动态upstream支持、一致性hash算法支持服务发现等,团队的研发效率和系统的可扩展性都无法得到更好的满足,最终也会体现在稳定性风险上。
- 一些稳定性能力提升的功能在最新nginx版本下已经得到了支持,比如worker_shutdown_timeout 和reuseport指令等,而我们还没有办法直接使用。
为了彻底解决这3个方面的稳定性风险,我们将接入引擎从2014年的tengine成功升级到2018年的nginx,同时进行了很多优化工作,主要收益如下:
修复了8个重要功能性能bug,其中5个在线上已经发生
进行了15项重要功能改进和优化,其中5个已经在线上触发问题。
解决了发布更新时部分实例流量抖动,严重时甚至cpu掉底的问题
解决了一致性hash算法在实例调权时全部接入引擎吞吐下降,业务剧烈抖动和报警的问题
创新性解决了srww算法在有哨兵场景下进行压测或者发布更新时服务剧烈抖动,严重时甚至cpu掉底的问题,相关patch正在整理中,计划提交给nginx官方社区,后续也会整理文章对外分享。
除了稳定性收益外,引擎升级新增了6个业务强需求的功能和5个业务有预期的功能,长远看对接入引擎长期演进也奠定了良好的稳定性和扩展性基础。
配置变更风险防控
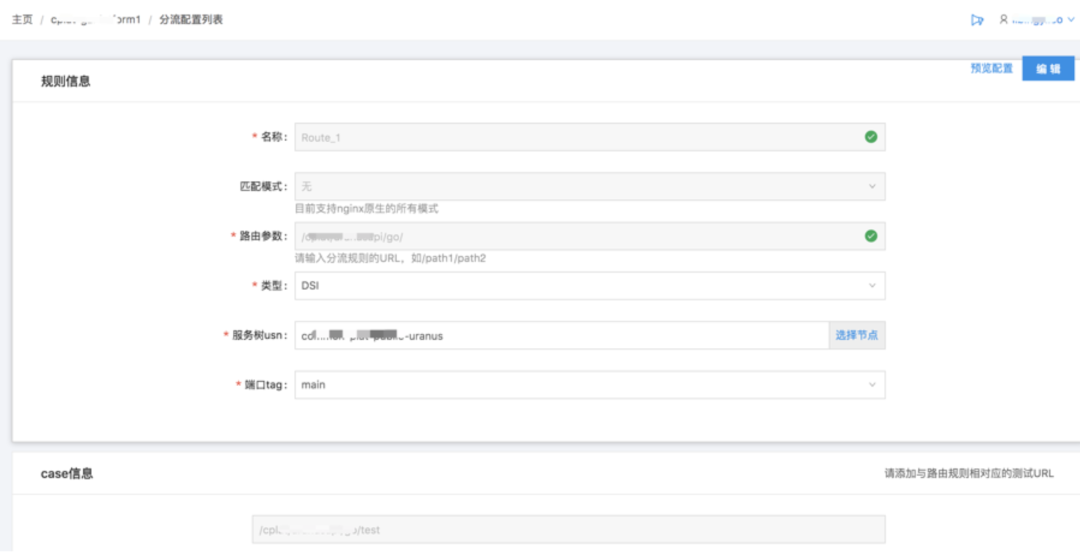
接入平台在2016和2017年分别有两次导致全平台故障的p1、p2(公司事故等级,最高p1)事故,原因全部为配置变更引起,接入平台的配置描述能力过于强大和灵活,在提供丰富灵活能力的同时不可避免会带来稳定性的隐患,因此配置变更的风险防控能力就作为稳定性保障的重中之重,我们设计实现了接入平台配置变更平台海姆,平台抽象和约束了接入引擎配置模型,同时将代码部署的风险防控能力全部复用到配置变更系统上,配置变更风险得到了较好的防控,再也没有出现过因为配置变更导致的p2+故障。海姆平台的主要风险防控特点如下:
预防能力:
配置模型的抽象和约束
配置语法检查和语义检查能力
配置强制review功能
配置分级发布功能(支持不同服务配置并行发布)
配置强制double check功能
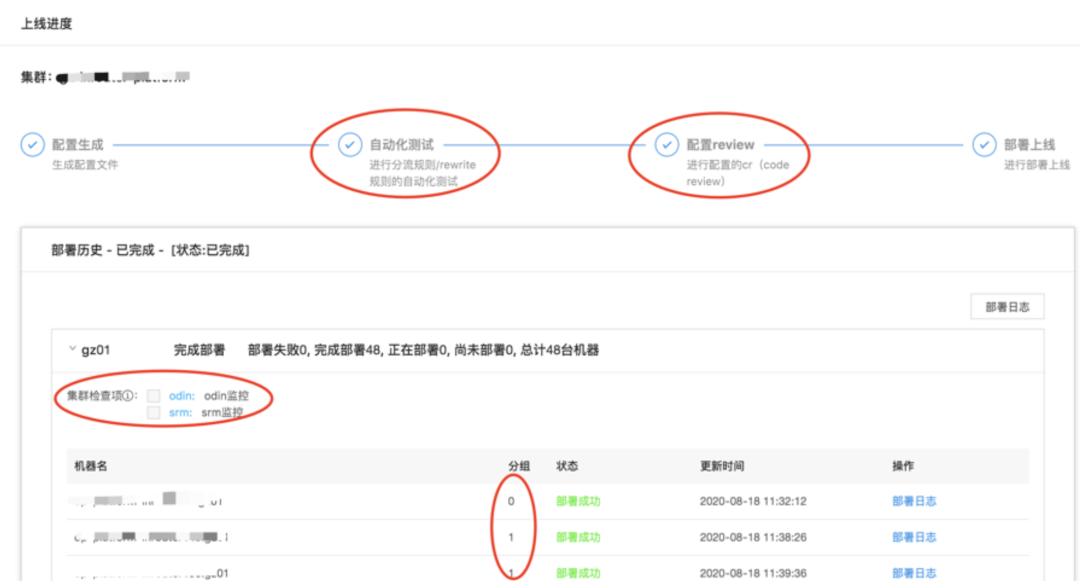
发现能力:
配置变更系统打通风险防控体系,服务有异常会自动进行风险提示和变更拦截。
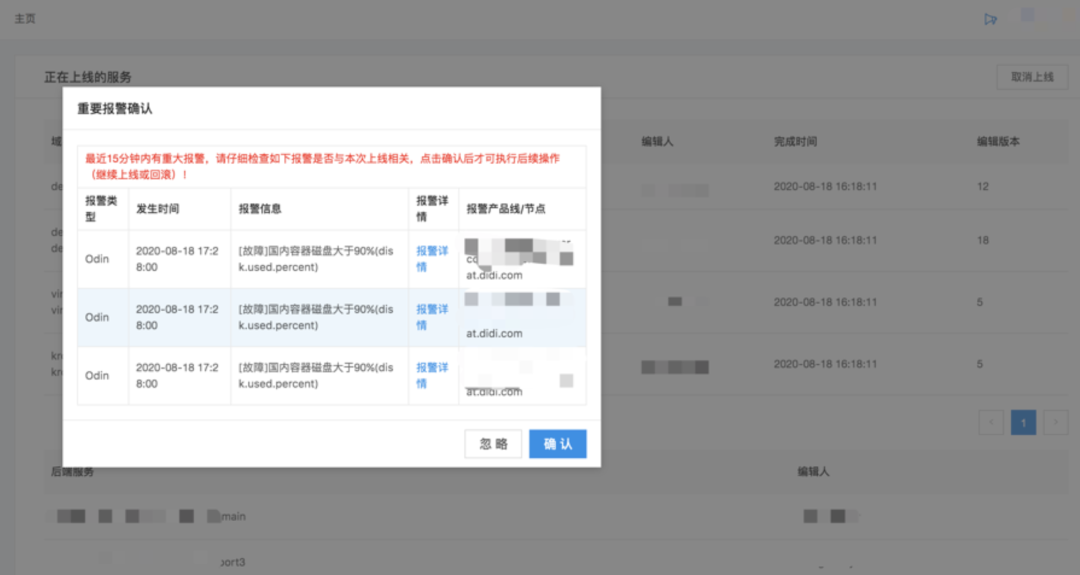
止损能力:
配置常态回滚和快速回滚能力
4. 云原生时代接入平台探索
多协议支持
多协议支持是云原生接入平台非常重要的一个能力,业内主流的数据面sidecar envoy/linkerd2-proxy/mosn等都具备多协议支持的能力,而滴滴东西向流量最广泛使用的协议就是http和thrift。
2019年随着接入平台对http协议流量管理和服务治理实践的成熟和thrift协议统一高效服务治理的迫切性,我们启动了接入引擎支持thrift协议的专项研发攻坚工作,目前已经在金融业务线进行了多个模块的落地,帮助业务解决了服务优雅发布、可观察性等痛点,最近Nginx官方社区也已经认可接受我们的代码作为第三方模块,目前正在开源筹备中,thrift接入引擎具备如下的特点:
通用thrift编解码器:
支持多种序列化协议,包括TBinaryProtocol、TcompactProtocol
支持多种传输层协议,包括Tsocket、TFramedTransport
协议编解码无需IDL
模块化设计,很好的可扩展性
编解码器提供通用接口,非nginx绑定,可以集成到其它代理中使用
基于树的灵活高效IDL字段Setter和Getter(Doing)
模块化设计:
转发能力模块化,可作为独立的第三方模块集成到nginx。
简单易用:
配置模型基本同http,简单易上手
功能强大:
和http打平的服务治理能力,包括可观察性、限流、路由等
高性能:
多进程异步无阻塞的编解码和请求转发模型
接入引擎mesh化
在集中式接入引擎诞生的5年多时间内,其持续在流量管理和服务治理上对业务稳定性保障进行赋能,随着云原生时代的到来和服务治理逐步进入深水区,集中式接入平台面临着新的挑战:
1. 极致的稳定性要求
集中式接入引擎始终有3个无法回避的稳定性隐患
① 多业务共享集群:
相互可能有影响:虽然通过稳定性机制建设的完善,近3年来没有因此带来稳定性事故,但共享集群的风险始终没有彻底根除,尤其在一些新功能开发和应用实践时始终如履薄冰,比如针对某个服务请求进行故障注入时理论上仍然可能对其它业务线带来影响。
② 鲁棒性较弱:
业务对接入引擎延时非常敏感(毫秒级要求),数万qps下接入引擎有时单机甚至单进程延时抖动就会对敏感业务带来较大影响,甚至触发业务线一级报警,运维同学承担着巨大的心理压力。
③ 容量边界的不确定性:
七层接入平台前往往还有一个四层接入代理,通过vip提供给业务方使用,二者对容量的精准评估和快速的弹性伸缩能力都有很高的要求,否则很有可能存在雪崩的归零风险。
2. 极致的运维效率
①接入引擎和业务服务生命周期不同,整个接入体验不好,效率较低。
② 转发规则的维护成本很高
以上2点导致服务治理能难以较低的成本进行规模化落地,我们正在联合业务团队、弹性云和研发云团队做接入引擎mesh化的探索工作,mesh化后以上的挑战将会得到很大程度的化解,目前正在仿真环境将接入引擎mesh化到客户端侧解决流量闭环的问题。
5. 总结
经过5年多的发展和演进,滴滴七层接入平台在稳定性能力建设、服务治理能力建设、云原生接入的探索取得了一些进展:
规模化的服务治理能力
支持公司全公司http服务限流预案400+、限流接口2400+、切流预案400+。
持全公司http服务的服务发现,涉及数千个服务。
支持全公司http服务可观察性能力建设,包括标准监控和细粒度多维度监控。
一级的稳定性保障能力
系统可用性>99.99%,转发延时<1ms,连续3年没有对业务可用性带来影响。
云原生接入引擎探索
完成接入引擎多协议的支持。
完成接入引擎mesh化探索,并打通相关控制面,即将在业务试点上线。
6. 未来展望
云原生接入引擎
云原生时代已经来临,我们相信在可见的未来,就像TCP/IP协议栈或者SDN一样,接入引擎一定会抽象出更通用的应用层流量管理和服务治理能力,作为sidecar下沉并固化在整个基础设施中,在屏蔽滴滴异构架构、异构技术栈、多语言、多协议业务特点进行规模化服务治理和将业务逻辑和基础施设解耦中发挥重大作用。
多模微服务治理
由于多BU、历史包袱、业务技术栈倾向的特点,未来的应用架构必然不可避免异构化,即便如此,接入引擎mesh化也不是银弹,它在很长时间内会需要和传统基于SDK的服务治理和基于集中式接入平台的服务治理形成合力、组合补位,以一套组合拳的方式共同保障滴滴全平台的稳定性,提升运维/研发/测试的效能。
一站式七层接入平台
从用户角度看,七层接入平台目前的定位仍然是一个专家系统,服务的用户主要是有着丰富运维经验的SRE,不管是接入引擎例行变更需求、问题分析定位还是服务治理能力赋能,业务RD更多情况下仍然需要寻求SRE的支持和帮助,这带来大量的沟通成本,进一步降低了整体业务交付效率,我们期望打造一个体验友好的一站式七层接入平台,业务RD和SRE都可以自助在平台上完成所有接入引擎相关工作,提高研发和运维的生产力。

团队介绍
滴滴云平台事业群服务中间件团队负责为公司提供统一的七层流量接入和服务治理基础设施,经过多年的技术沉淀,团队在微服务框架、云原生服务治理、网络协议、访问质量、负载均衡、代理技术等领域积累了丰富的经验,我们一直致力于构建稳定、高效、易用、通用的流量接入和服务治理平台,相关产品和平台在滴滴均有大规模的实践应用和落地。
作者介绍

滴滴服务中间件团队负责人,多年高并发、高吞吐系统设计研发经历,在微服务治理和稳定性建设领域有较丰富的经验,对云原生技术感兴趣,曾就职于百度,从事统一接入系统研发和运维工作。
延伸阅读


内容编辑 | Teeo
联系我们 | DiDiTech@didiglobal.com
滴滴技术 出品
没有评论:
发表评论