基础篇
SQL语言按照功能划分
DDL(DataDefinitionLanguage),也就是数据定义语言,它用来定义我们的数据库对象,包括 数据库、数据表和列。通过使用DDL,可以创建,删除和修改数据库和表结构。
DDL的基础语法及设计工具
- 对数据库进行定义
CREATE DATABASE nba; // 创建一个名为nba的数据库DROP DATABASE nba; // 删除一个名为nba的数据库
- 对数据表进行定义
CREATE TABLE table_name
创建表结构
CREATE TABLE player ( player_id int(11) NOT NULL AUTO_INCREMENT, player_name varchar(255) NOT NULL);
修改表结构
// 修改字段ALTER TABLE player ADD (age int(11));// 修改字段名 ALTER TABLE player RENAME COLUMN age to player_age // 修改字段的数据库类型 ALTER TABLE player MODIFY (player_age float(3,1)); // 删除字段 ALTER TABLE player DROP COLUMN player_age;
数据标的常见约束
目的:
保证RDBMS里面数据的准确性和一致性。
常见的约束:
- 主键约束
- 一条记录的唯一标识,不能重复,不能为空。
- 可以是一个字段,也可以由多个字段符合组成。
- 外键约束
- 一个表中的外键对应另一张表中的主键。
- 可重复,也可为空。
- 唯一性约束
- NOT NULL约束
- DEFAULT,表明字段的默认值。
- CHECK约束
我们常通过可视化管理和设计工具进行数据库的设计。例如:Navicat
DML(DataManipulationLanguage),数据操作语言,我们用它操作和数据库相关的记录,比 如增加、删除、修改数据表中的记录。
DCL(DataControlLanguage),数据控制语言,我们用它来定义访问权限和安全级别。
DQL(DataQueryLanguage),数据查询语言,我们用它查询想要的记录。
DB、DBS和DBMS的区别是什么?
DB(DataBase),也就是数据库。
DBS(DataBase System),也就是数据库系统。它是更大的概念,包括了数据库、数据库管理系统以及数据库管理人员DBA。
DBMS(DataBase Management System),也就是数据库管理系统。DBMS = 多个数据库(DB) + 管理程序。
平常我们说的Oracle、MySQL等称之为数据库,但确切讲,它们应该是数据库管理系统,即DBMS。
DBMS分类
关系型数据库(RDBMS)和非关系型数据库(NoSQL)
关系型数据库就是建立在关系模型基础上的数据库,SQL就是关系数据库的查询语言。
非关系数据库分类很多,主要有以下这些:
- 键值型数据库:通过Key - Value键值的方式来存储数据。其中,Redis是最流行的键值型数据库。
- 文档型数据库:用来管理文档,在数据库中文档作为处理信息的基本单位,一个文档就相当于一条记录。其中,MongoDB是最流行的文档型数据库。
- 搜索引擎
- 列式数据库
- 图形数据库
SQL是如何执行的?
- Oracle中的SQL在Oracle中的执行过程:

- 语法检查: 检查SQL拼写是否正确,如果不正确,Oracle会报语法错误。
- 语义检查: 检查SQL中的访问对象是否存在。语法检查和语义检查的作用是保证SQL语句没有错误。
- 权限检查: 看用戶是否具备访问该数据的权限。
- 共享池检查: 共享池(SharedPool)是一块内存池,最主要的作用是缓存SQL语句和该语句的执行计
划。
Oracle通过检查共享池是否存在SQL语句的执行计划,来判断进行软解析,还是硬解析。
如何理解软解析和硬解析?
在共享池中,Oracle首先对SQL语句进行Hash运算,然后根据Hash值在库缓存(Library Cache)中查 找,如果存在SQL语句的执行计划,就直接拿来执行,直接进入"执行器"的环节,这就是软解析。
如果没有找到SQL语句和执行计划,Oracle就需要创建解析树进行解析,生成执行计划,进入"优化 器"这个步骤,这就是硬解析。
共享池是Oracle中的术语,包括了库缓存,数据字典缓冲区等。
如何避免硬解析,尽量使用软解析?
在Oracle中,绑定变量是它的一大特色。绑定变量就是在SQL语句中使用变量,通过不同的变量取值来改变SQL的执行结果。这样做的好处是能提升软解析的可能性,不足之处在于可能会导致生成的执行计划不够优化,因此是否需要绑定变量还需要视情况而定。
- 优化器: 优化器中就是要进行硬解析,也就是决定怎么做,比如创建解析树,生成执行计划。
- 执行器: 当有了解析树和执行计划之后,就知道了SQL该怎么被执行,这样就可以在执行器中执行语句
了。
- MySQL中的SQL是如何执行的
MySQL是典型的C/S架构,即Client/Server架构,服务器端程序使用的mysqld。整体的MySQL流程如下图所示:

MySQL由三层组成:
- 连接层:客户端和服务端建立连接,客户端发送SQL至服务器端;
- SQL层:对SQL语句进行查询处理;
- 存储引擎层:与数据库文件打交道,负责数据的存储和读取。
其中,SQL层与数据库文件的存储方式无关,SQL层结构如下:
 1. 查询缓存: Server如果在查询缓存中发现了这条SQL语句,就会直接将结果返回给客戶端;如果没有,就进入到解析器阶段。需要说明的是,因为查询缓存往往效率不高,所以在My拼SQ课L8.0之后就抛弃了这个功能。
1. 查询缓存: Server如果在查询缓存中发现了这条SQL语句,就会直接将结果返回给客戶端;如果没有,就进入到解析器阶段。需要说明的是,因为查询缓存往往效率不高,所以在My拼SQ课L8.0之后就抛弃了这个功能。
2. 解析器: 在解析器中对SQL语句进行语法分析、语义分析。
3. 优化器: 在优化器中会确定SQL语句的执行路径,比如是根据全表检索,还是根据索引来检索等。
4. 执行器: 在执行之前需要判断该用戶是否具备权限,如果具备权限就执行SQL查询并返回结果。在
MySQL8.0以下的版本,如果设置了查询缓存,这时会将查询结果进行缓存。
这部分与Oracle执行SQL的原理是一样的。
与Oracle不同的是,MySQL的存储引擎采用了插件的形式,每个存储引擎都面向一种特定的数据库应用环境。同时开源的MySQL还允许开发人员设置自己的存储引擎,下面是一些常见的存储引擎:
- InnoDB存储引擎:它是MySQL5.5版本之后默认的存储引擎,最大的特点是支持事务、行级锁定、外键 约束等。
- MyISAM存储引擎:在MySQL5.5版本之前是默认的存储引擎,不支持事务,也不支持外键,最大的特点 是速度快,占用资源少。
- Memory存储引擎:使用系统内存作为存储介质,以便得到更快的响应速度。不过如果mysqld进程崩 溃,则会导致所有的数据丢失,因此我们只有当数据是临时的情况下才使用Memory存储引擎。
- NDB存储引擎:也叫做NDBCluster存储引擎,主要用于MySQLCluster分布式集群环境,类似于Oracle 的RAC集群。
- Archive存储引擎:它有很好的压缩机制,用于文件归档,在请求写入时会进行压缩,所以也经常用来做 仓库。
设计数据表的原则
"三少一多"
- 数据表的个数越少越好
- 数据表中的字段个数越少越好
- 数据表中联合主键的字段个数越少越好
- 使用主键和外键越多越好
SELECT查询的基础语法
一般在生产环境下,不推荐直接使用SELECT*进行查询。(因为效率不高)
// 查询列 colmns代指需要查询列(* 查询全部,但在生产环境中较少使用,影响效率); tablename为表名SELECT columns FROM tablename// 起别名SELECT name AS n, hp_max AS hm// 查询常数SELECT '王者荣耀' AS platfor, name FROM heros// 去除重复行// DISTINCT需要放到所有列名的前面; DISTINCT其实是对后面所有列名的组合进行去重SELECT DISTINCT attack_range FROM heros// 如何排序检索数据( ORDER BY 子句 默认按ASC递增排序)// ORDER BY 通常位于 SELECT 语句的最后一条子句SELECT name, hp_max FROM heros ORDER BY mp_max, hp_max DESC// 约束返回结果的数量 LIMIT// 约束返回结果的数量可以减少数据表的网络传输量,也可以提升查询效率。SELECT name, hp_max FROM heros, ORDER BY hp_max DESC LIMIT 5
- SELECT的执行顺序
- 关键字的顺序是不能颠倒的:
SELECT...FROM...WHERE...GROUP BY...HAVING...ORDER BY...
- SELECT语句的执行顺序(在MySQL和Oracle中,SELCT执行顺序基本相同):
FROM > WHERE > GROUP BY > HAVING > SELCT的字段 > DISTINCT > ORDER BY > LIMIT
// 例如一个SQL语句,执行顺序如下:SELECT DISTINCT palyer_id, player_name, count(*) as num #顺序5FROM player JOIN team ON player.team_id = team.team_id #顺序1WHERE height > 1.80 #顺序2GROUP BY player.team_id #顺序3HAVING num > 2 #顺序4ORDER BY num DESC #顺序6LIMIT 2 #顺序7
在SELECT语句执行这些步骤的时候,每个步骤都会产生一个虚拟表,然后将这个虚拟表传入下一个步骤中作为输入。
SQL的执行原理
SQL语句的SELECT是先执行FROM这一步的。在这个阶段,如果是多张表联查,还会经历下面的几个步骤:
- 首先先通过CROSS JOIN求笛卡尔积,相当于得到虚拟表vt(virtual table)1-1;
- 通过on进行筛选,在虚拟表vt1-1的基础上进行筛选,得到虚拟表vt1-2;
- 添加外部行。如果我们使用的是左连接、右连接或者全连接,就会涉及外部行,也就是在虚拟表vt1-2的基础上增加外部行,得到虚拟表vt1-3。
如果操作的是两张以上的表,还会重复上面的步骤,直到所有表都被处理完为止。这个过程得到是原始数据,也就是最终的虚拟表vt1,就可以在这个基础上再进行WHERE阶段。在这个阶段中,会根据vt1表的结果进行筛选过滤,得到虚拟表vt2。
然后进入第三步和第四步,也就是GROUP和HAVING阶段。在这个阶段中,实际上是在虚拟表vt2的基础上进行分组和分组过滤,得到中间的虚拟表vt3和vt4。
完成条件筛选部分后,就可以筛选表中提取的字段,也就是进入到SELECT和DISTINCT阶段。
首先在SELECT阶段会提取想要的字段,然后在DISTINCT阶段过滤重复的行,分别得到中间的虚拟表vt5-1和vt5-2。
当提取了想要的字段后,就可以按照指定的字段进行排序,也就是ORDER BY阶段,得到虚拟表vt6。
最后在vt6的基础上,取出指定行的记录,也就是LIMIT阶段,得到最终的结果,对应的是虚拟表vt7。
提升查询效率的手段
- 尽量少使用SELECT*,它会查询所有列,效率不高;
- 当你知道查询中有n条记录或者需要n条记录时,可以使用LIMIT n进行约束,从而提高查询效率;
- 指定筛选条件,进行过滤。过滤可以筛选符合条件的结果,并进行返回,减少不必要的数据行。
- 尽量少使用通配符,因为它需要消耗数据库更长的时间进行匹配。
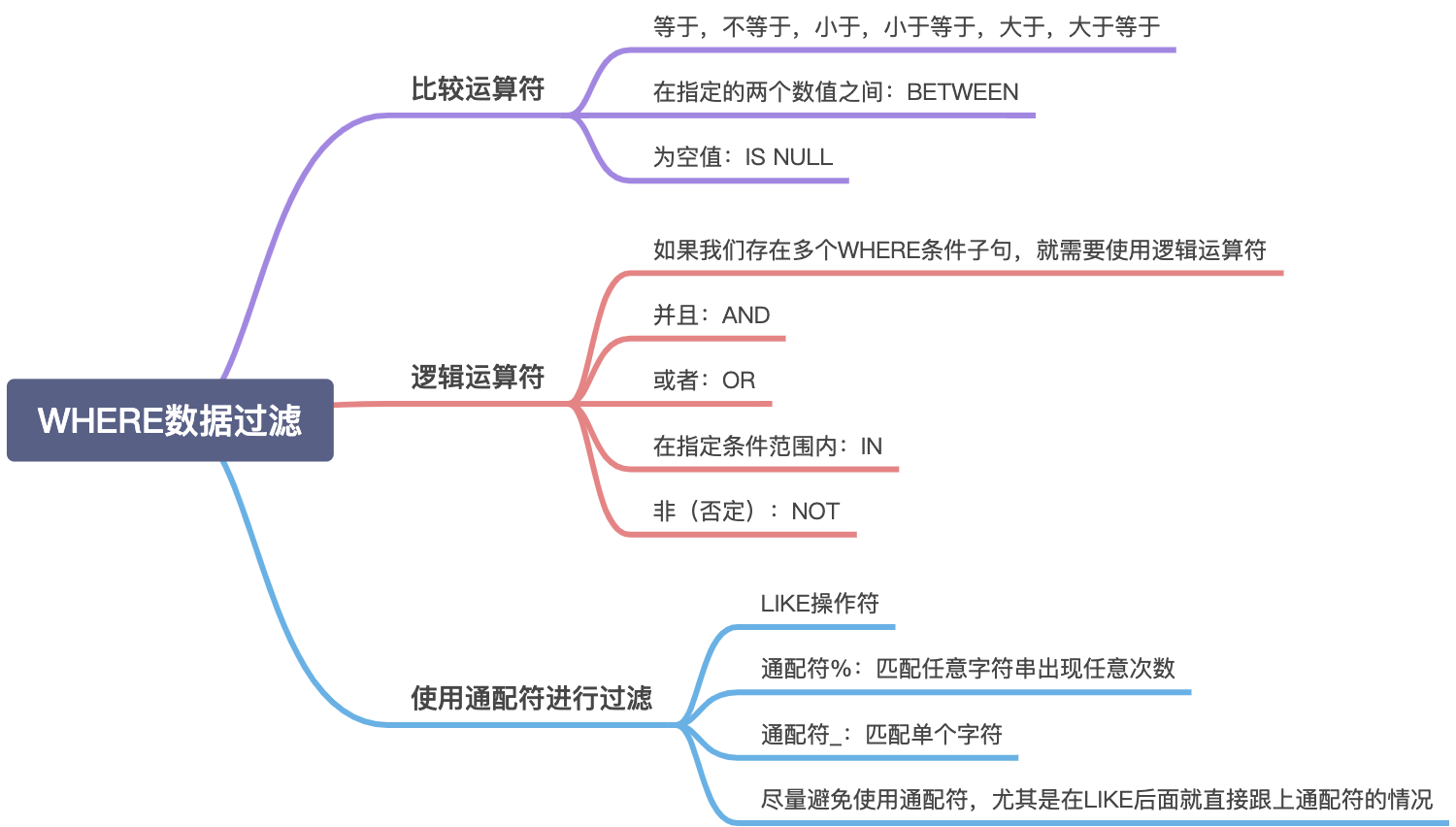
SQL数据过滤的方法
子查询
子查询既嵌套在查询中的查询,有便于我们进行更复杂的查询。
它划分为关联子查询和非关联子查询。
- 关联子查询
子查询需要执行多次,采用循环的方式,先从外部查询开始,每次都传入子查询进行查询,然后再将结果反馈给外部,这种嵌套的执行方式就称为关联子查询。
SELECT player_name, height, team_id FROM player AS a WHERE height > (SELECT avg(height) FROM player AS b WHERE a.team_id = b.team_id
- 非关联子查询
子查询从数据表中查询了数据结果,如果这个数据结果只执行一次,然后这个数据结果作为主查询的条件进行执行,那么这样的子查询叫做非关联子查询。
SELECT player_name, height FROM player WHERE height = (SELECT max(height) FROM player)
- 子查询中的关键字
EXISTS子查询
关联子查询通常也会和EXISTS子查询一起使用。EXISTS子查询用来判断条件是否满足,满足为True,不满足为False。
集合比较子查询(IN、ANY、ALL、SOME)
IN:判断是否在集合中
ANY:需要与比较操作符一起使用,与子查询返回的任何值做比较
ALL:需要与比较操作符一起使用,与子查询返回的任何值做比较
SOME:实际上是ANY的别名,作用相同,一般常使用ANY
- 子查询作为计算字段
把子查询的结果作为主查询的列
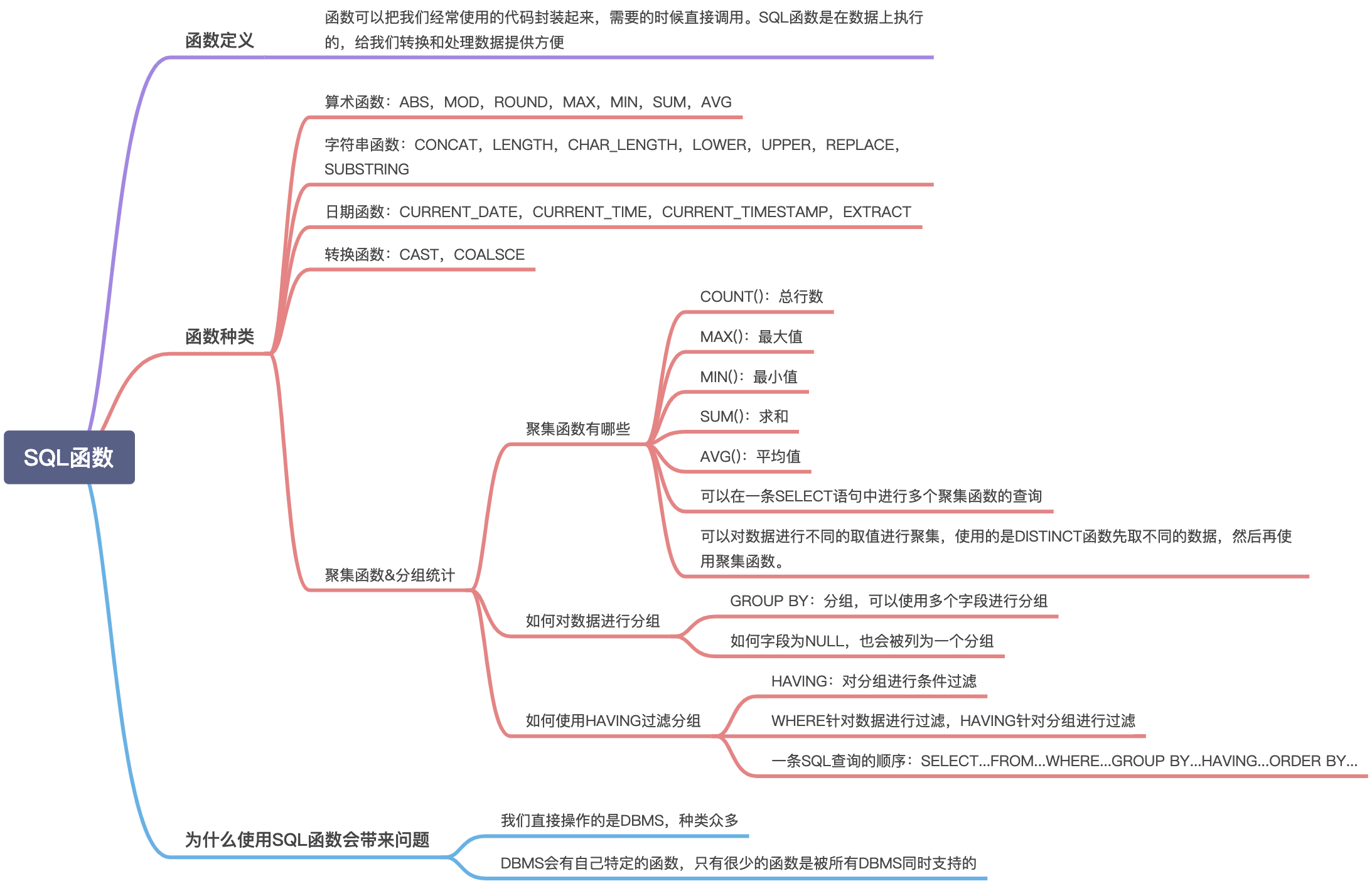
SQL函数
SQL标准
SQL存在不同版本的标准规范,因为不同规范下的表连接操作是有区别的。其有两个主要的标准,分别是SQL92和SQL99。
SQL92
- 在SQL92中是如何使用连接的
SQL92的5种连接方式,它们分别是笛卡尔积、等值连接、非等值连接、外连接(左连接、右连接)和自连接。
笛卡尔积(交叉连接)CROSS JOIN
笛卡尔积是一个数学运算。假设两个集合X和Y,X和Y的笛卡尔积就是X和Y的所有可能组合。
它的作用就是可以把任何表进行连接,即使这两张表不相关。
等值连接
两张表的等值连接就是用两张表中都存在的列进行连接。也可以对多张表进行等值连接。
非等值连接
进行多表查询的时候,如果连接多个表的条件是等号时,就是等值连接,其他的运算符连接就是非等值查询。
外连接
两张表的外连接,会有一张主表,另一张是从表。如果是多张表的外连接,那么第一张表是主表,即显示全部的行,而剩下的表则显示对应连接的信息。
在SQL92中才用(+)代表从表所在的位置,其只有左外连接和右外连接,没有全外连接。
左外连接:
指左边的表是主表,需要显示左边表的全部行,而右侧的表是从表,(+)表示哪个是从表。
右外连接:
指的是右边的表是主表,需要显示右边表的全部行,而左侧的是从表。
自连接
自连接可以对多个表进行操作,也可以对同一个表进行操作。也就是说查询条件使用了当前表的字段。
SQL99
交叉连接
即SQL92中的笛卡尔乘积,这里采用的是CROSS JOIN。
自然连接
即SQL92的等值连接。这里采用的是NATURAL JOIN。
// SQL92SELECT player_id, a.team_id, player_name, height, team_name FROM player as a, team as b WHERE a.team_id = b.team_id// SQL99SELECT player_id, team_id, player_name, height, team_name FROM player NATURAL JOIN team
ON连接
ON连接用来指定想要的连接条件。
一般来说在SQL99中,需要连接的表会采用JOIN进行连接,ON指定了连接条件,后面可以是等值连接,也可以采用非等值连接。
USING连接
使用USING指定数据表里同名字段进行等值连接。使用JOIN USING可以简化JOIN ON的等值连接。例如:
// JOIN ONSELECT player_id, player.team_id, player_name, height, team_name FROM player JOIN team ON player.team_id = team.team_id// JOIN USINGSELECT player_id, team_id, player_name, height, team_name FROM player JOIN team USING(team_id)
外连接
SQL99的外连接包括三种形式:
- 左外连接:LEFT JOIN 或 LEFT OUTER JOIN
- 右外连接:RIGHT JOIN 或 RIGHT OUTER JOIN
- 全外连接:FULL JOIN 或 FULL OUTER JOIN
MySQL不支持全外连接,否则的话全外连接会返回左表和右表中的所有行。
全外连接的结果 = 左右表匹配的数据 + 左表没有匹配到的数据 + 右表没有匹配到的数九
自连接
自连接的原理在SQL92和SQL99中都是一样的,只是表述方式不同。
SQL99和SQL92的区别
- 两者的连接方式略有不同,这些连接操作基本可以分为三种情况:
- 内连接:将多个表之间满足连接条件的数据行查询出来。它包括了等值连接、非等值连接和自连接。
- 外连接:会返回一个表中的所有记录,以及另一个表中匹配的行。它包括了左外连接、右外连接和全连接。
- 交叉连接:也称为笛卡尔积,返回左表中每一行与右表中每一行的组合。在SQL99中使用CROSS JOIN。
- SQL99相对SQL92,写法更加可读和严谨
在SQL92中进行查询时,会把所有需要连接的表都放到FROM之后,然后在WHERE中写明连接的条件。
而在SQL99中这方面更灵活,它不需要一次性把所有需要连接的表都放到FROM之后,而是采用JOIN的方式,每次连接一张表,可以多次使用JOIN进行连接。
SELECT ... FROM table1 JOIN table2 ON table1和table2的连接条件 JOIN table3 ON table2和table3的连接条件
多表连接建议使用SQL99标准,因为层次性更强,可读性更强
视图
视图即虚拟表,它相当于是一张表或多张表的数据结果集。

通常情况下,小型项目的数据库可以不使用视图,但是在大型项目中,以及数据表比较复制的情况下,视图的价值就凸显出来了,它可以帮助我们把经常查询的结果集放到虚拟表中,提升使用效率。
视图的操作
- 创建视图:CREATE VIEW
// 语法CREATE VIEW view_name ASSELECT column1, column2FROM tableWHERE condition// 实例CREATE VIEW player_above_avg_height ASSELECT player_id, heightFROM playerWHERE height > (SELECT AVG(height) from player)
- 嵌套视图
CREATE VIEW player_above_above_avg_height ASSELECT player_id, heightFROM playerWHERE height > (SELECT AVG(height) from player_above_avg_height)
- 修改视图:ALTER VIEW
ALTER VIEW view_name AS SELECT column1, column2 FROM tableWHERE condition
- 删除视图:DROP VIEW
DROP VIEW view_name
如何使用视图简化SQL操作
- 视图的作用:封装SQL查询,提升SQL复用率
- 利用视图完成复杂的连接
- 利用视图对数据进行格式化
- 使用视图和计算字段
视图 VS 临时表
- 视图是虚拟表,临时表是实体表。
- 临时表只在当前连接存在,关闭连接后,临时表就会自动释放。
存储过程
存储过程(Stored Procedure)是程序化的SQL,可以直接操作底层数据表,相比于面向集合的操作方式,能够实现一些更复杂的数据处理。它由SQL语句和流控制语句共同组成。
CREATE PROCEDURE 存储过程名称([参数列表])BEGIN 需要执行的语句END
与视图类型,删除存储过程使用的是DROP PROCEDURE;更新存储过程为ALTER PROCEDURE。
下面看一个简单的例子:
// 1+2+...+nCREATE PROCEDURE `add_num`(IN n INT)BEGIN DECLARE i INT; DECLARE sum INT; SET i = 1; SET sum = 0; WHILE i <= n DO SET sum = sum + i; SET i = i + 1; END WHILE; SELECT sum;END
如果需要再次使用这个存储过程时,直接使用CALL add_num(50);即可。
三种参数类型
参数类型 | 是否返回 | 作用 |
IN | 否 | 向存储过程传入参数,存储过程中修改该参数的值,不能被返回。 |
OUT | 是 | 把存储过程计算的结果放到该参数中,调用者可以得到返回值。 |
INOUT | 是 | IN和OUT的结合,既用于存储过程的传入参数,同时又可以把计算结果放到参数中,调用者可以得到返回值 |
IN和OUT的结合,既用于存储过程的传入参数,同时又可以把计算机结果放到参数中,调用者可以得到返回值。
IN参数必须在调用过程时指定,而在存储过程中修改该参数的值不能被返回。而OUT参数和INOUT参数可以在存储过程中被改变,并可返回。
例如如下:
// 查询某一类型英雄中的最大的最大生命值,最小的最大魔法值,以及平均最大攻击值CREATE PROCEDURE `get_hero_scores`( OUT max_max_hp FLOAT, OUT min_max_mp FLOAT, OUT avg_max_attack FLOAT, s VARCHAR(255) )BEGIN SELECT MAX(hp_max), MIN(mp_max), AVG(attack_max) FROM heros WHERE role_main = s INTO max_max_hp, min_max_mp, avg_max_attackEND// 进行调用CALL get_hero_scores(@max_max_hp, @min_max_mp, @avg_max_attack, '战士');SELECT @max_max_hp, @min_max_mp, @avg_max_attack;
流控制语句
- BEGIN...END
其中间包含了多个语句,每个语句都以(;)号为结束符。
- DECLARE
用于声明变量,使用的位置在于BEGIN...END语句中间,而且需要在其他语句之前进行变量的声明。
- SET
赋值语句,用于对变量进行赋值。
- SELECT...INTO
把从数据表中查询的结果存放到变量中,也就是为变量赋值。
- IF...THEN...ENDIF
条件判断语句,我们还可以在iF...THEN...ENDIF中使用ELSE和ELSEIF来进行条件判断。
- CASE
用于多条件的分支判断,语法如下:
CASE WHEN expression1 THEN ... WHEN expression2 THEN ... ... ELSE --ELSE可加可不加。加的话代表所有条件都不满足时采用的方式END
- LOOP、LEAVE和ITERATE
LOOP是循环语句,使用LEAVE可以跳出循环,使用ITERATE则可以进入下一 次循环。如果你有面向过程的编程语言的使用经验,你可以把LEAVE理解为BREAK,把ITERATE理解为 CONTINUE。
- REPEAT...UNTIL...END REPEAT
这是一个循环语句,首先会执行一次循环,然后在UNTIL中进行表达式 的判断,如果满足条件就退出,即END REPEAT;如果条件不满足,则会就继续执行循环,直到满足退出条 件为止。
- WHILE...DO...END WHILE
这也是循环语句,和REPEAT循环不同的是,这个语句需要先进行条件判断, 如果满足条件就进行循环,如果不满足条件就1退出循环。
优缺点
有些公司对于大型项目要求使用存储过程,而有些则在手册中明确禁止使用存储过程。
- 优点
- 一次编译多次使用,提升SQL的执行效率
- 减少开发工作量
- 安全性强
- 减少网络传输量
- 缺点
- 可移植性差
- 调试困难
- 版本管理困难
- 不适合高并发的场景
事务处理
保证了一次处理的完整性,也保证了数据库中的数据一致性。
特性:ACID
- A,原子性(Atomicity)。进行数据处理操作的基本单位。
- C,一致性(Consistency)。指的是数据库在进行事务操作后,会由原来的一致状态,变成另一种一致的状态。
- I,隔离性(Isolation)。每个事务都是彼此独立的,不会受到其他事务的执行影响。
- D,持久性(Durability)。事务提交之后对数据的修改是持久性的,即使在系统出故障的情况下,比如系统崩溃或者存储介质发送故障,数据的修改依然是有效的。持久性是通过事务日志来保证的。日志包括了回滚日志和重做日志。
ACID是事务的四大特性。原子性是基础,隔离性是手段,一致性是约束条件,而持久性使我们的目的。
事务的控制
使用事务有两种方式,分为隐式事务和显式事务。隐式事务实际上就是自动提交,Oracle默认不自动提交,需要手动COMMIT命令,而MySQL默认自动提交。
- 常用的控制语句
- STARTTRANSACTION或者BEGIN,作用是显式开启一个事务。
- COMMIT: 提交事务。当提交事务后,对数据库的修改是永久性的。
- ROLLBACK或者ROLLBACKTO[SAVEPOINT],意为回滚事务。意思是撤销正在进行的所有没有提交的修
改,或者将事务回滚到某个保存点。 - SAVEPOINT: 在事务中创建保存点,方便后续针对保存点进行回滚。一个事务中可以存在多个保存点。
- RELEASESAVEPOINT: 删除某个保存点。
- SETTRANSACTION,设置事务的隔离级别。
事务隔离
- 事务并发处理可能存在的异常都有哪些?
共有3种异常情况:脏读(Dirty Read)、不可重复读和幻读(Phantom Read)
- 脏读:读到了其他事务还没有提交的数据。
- 不可重复读:对某数据进行读取,发现两次读取的结果不同,也就是说没有读到相同的内容。这是因为有其他事务对这个数据同时进行了修改或删除。
- 幻读:事务A根据条件查询得到了N条数据,但此时事务B更改或者增加了M条符合事务A查询条件的数据,这样事务A再次进行查询的时候会发现会有N+M条数ujuu,产生了幻读。
- 事务隔离的级别有哪些?
| 脏读 | 不可重复读 | 幻读 |
读未提交(READ UNCOMMITTED) | 允许 | 允许 | 允许 |
读已提交(READ COMMITTED) | 禁止 | 允许 | 允许 |
可重复读(REPEATABLE READ) | 禁止 | 禁止 | 允许 |
可串行化(SERIALIZABLE) | 禁止 | 禁止 | 禁止 |
读未提交,也就是允许读到未提交的数据,这种情况下查询是不会使用锁的,可能会产生脏读、不可重复 读、幻读等情况。
读已提交就是只能读到已经提交的内容,可以避免脏读的产生,属于RDBMS中常⻅的默认隔离级别(比如说Oracle和SQL Server),但如果想要避免不可重复读或者幻读,就需要我们在SQL查询的时候编写带加锁 的SQL语句(我会在进阶篇里讲加锁)。
可重复读,保证一个事务在相同查询条件下两次查询得到的数据结果是一致的,可以避免不可重复读和脏读,但无法避免幻读。MySQL默认的隔离级别就是可重复读。
可串行化,将事务进行串行化,也就是在一个队列中按照顺序执行,可串行化是最高级别的隔离等级,可以解决事务读取中所有可能出现的异常情况,但是它牺牲了系统的并发性。
游标
游标,一种灵活的操作方式,可以让我们从数据结果集中每次提取一条数据记录进行操作。
在SQL中,游标是一种临时的数据库对象,可以指向存储在数据库表中的数据行指针。这里游标充当了指针的作用,可以通过操作游标来对数据行进行操作。
- 如何使用游标?
一般需要经历五个步骤。不同DBMS中,使用游标的语法可能略有不同。
1、定义游标
// 适用于MySQL,SQL Server,DB2和MariaDBDECLARE cursor_name CURSOR FOR select_statement// Oracle / PostgreSQLDECLARE cursor_name CURSOR IS select_statement
2、打开游标
OPEN cursor_name
3、从游标中取得数据
FETCH cursor_name INTO var_name ...
这句话的作用是使用cursor_name这个游标来读取当前行,并且将数据保存到var_name这个变量中,游标指针指到下一行。如果游标读取的数据行有多个列明,则在INTO关键字后面赋值多个变量名即可。
4、关闭游标
CLOSE cursor_name
5、释放游标
DEALLOCATE PREPARE
- 简单例子
假设想用游标扫描heros数据表中的数据行,然后累计最大生命值。
CREATE PROCEDURE `calc_hp_max`()BEGIN -- 创建接收游标的变量 DECLARE hp INT; -- 创建总数变量 DECLARE hp_sum INT DEFAULT 0; -- 创建结束标志变量 DECLARE done INT DEFAULT false; -- 定义游标 DECLARE cur_hero CURSOR SELECT hp_max FROM heros; OPEN cur_hero; read_loop:LOOP FETCH cur_hero INTO hp; -- 判断游标的训话是否结束 IF done THEN LEAVE read_loop; END IF SET hp_sum = hp_sum + hp; END LOOP; CLOSE cur_hero SELECT hp_sum; DEALLOCATE PREPARE cur_hero; END
- 游标性能
- 好处:灵活性强,可以解决复杂的数据处理问题,对数据进行逐行扫描处理
- 不足:使用游标的过程中会对数据进行加锁,当业务并发量大的时候,会影响到业务的效率。同时游标是在内存中进行的处理,会消耗系统资源,容易造成内存补足。
- 建议:通常游标有替代方案的时候,可以采用替代方案,如果实在绕不开有时候还是会用到游标。
原文转载:http://www.shaoqun.com/a/608585.html
e邮宝:https://www.ikjzd.com/w/594.html?source=tagwish
acca:https://www.ikjzd.com/w/1370
基础篇SQL语言按照功能划分DDL(DataDefinitionLanguage),也就是数据定义语言,它用来定义我们的数据库对象,包括数据库、数据表和列。通过使用DDL,可以创建,删除和修改数据库和表结构。DDL的基础语法及设计工具对数据库进行定义CREATEDATABASEnba;//创建一个名为nba的数据库DROPDATABASEnba;//删除一个名为nba的数据库对数据表进行定义CRE
taofenba:https://www.ikjzd.com/w/1725
空中云汇:https://www.ikjzd.com/w/2684
芒果店长:https://www.ikjzd.com/w/1533
云途物流:东欧跨境电商这块"小鲜肉",你确定不咬一口?:https://www.ikjzd.com/home/135653
口述:老婆当着我的面约会网友 彻夜未归:http://lady.shaoqun.com/m/a/117240.html
案值40亿元的走私案!他们走私的是什么?:https://www.ikjzd.com/home/103371
没有评论:
发表评论