数据湖仓
自从Databricks提出Lakehouse后,同时Snowflake的上市,湖仓一体成为数据领域最火热的话题。

https://databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html
核心的理念是Delta Lake使Hadoop有了ACID事务能力,使用Spark内存做实时,批,AI计算层。
这样就可以用分布式文件存储颠覆关系数据库存储。
数据仓库
数仓一直有3种类型,概念上和物理上:
一体机 | Oracle Exadata,Teradata | 价格,软硬件无法解耦 |
MPP | Greenplum | 数据分片始终会遇到数据倾斜问题 |
数据库 | Oracle,SQL Server | 100T以下容量数仓,使用列存储索引 |
//Snowflake是介于一体机和MPP之间的一种
//Hive没有事务,不支持update
数仓&BI架构

https://docs.microsoft.com/en-us/power-bi/guidance/center-of-excellence-business-intelligence-solution-architecture
数据湖仓定义
数据湖仓库可以分解为两种类型的架构:
第一种是数据湖(以使用读取存储模式的形式),称之为NOEDW,
第二种数据湖和关系数据库(以企业数据仓库或 EDW 的形式),将称之为ProEDW
对于 NoEDW,我的思维过程是,如果您试图使数据湖像关系数据库一样工作,为什么不只使用关系数据库呢?然后让数据湖做它擅长的事情, 关系数据库做它擅长的事情?
将关系数据库纳入数据湖仓的额外成本、复杂性和价值时间是值得的,原因有很多,其中之一是关系数据库将元数据与数据相结合,与在许多情况下元数据与数据分离的数据湖相比,自助 BI 更容易。当您处理来自许多不同来源的数据时,这种情况变得更加明显。
https://www.jamesserra.com/archive/2021/01/data-lakehouse-defined/
这篇blog很好的解析了数据湖仓概念。
很多家厂商在提湖仓一体的产品,主要是4种开源组合:
- Hadoop(Hudi)-存储
- Presto做虚拟连接-联邦查询
- Spark内存计算-ETL
- PostgreSQL MPP-数据集市
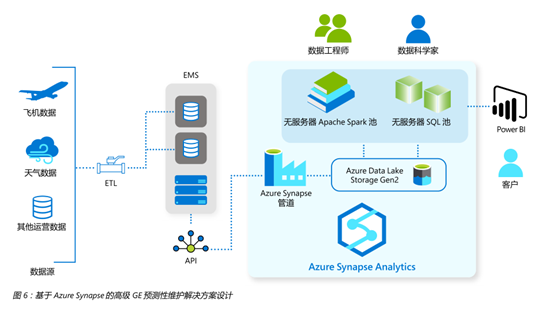
Azure Synapse Analytics Serverless
目前最成熟的商业产品就是Azure Synapse Analytics

- MPP数仓和无服务器SQL
- 用于大数据的Databricks/Spark
- Low/No Code的ETL/ELT数据编排
- 一站式Web开发环境
- 与 Power BI、CosmosDB 和 AzureML等深度集成
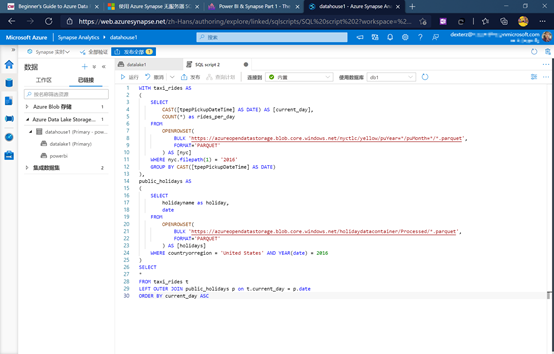
功能有很多就不展开介绍了,这次只谈Azure Synapse Analytics Serverless,核心有2点:
- 用户界面就是SQL Server
- 使用T-SQL查询对象存储文件

https://docs.microsoft.com/zh-cn/azure/synapse-analytics/sql/on-demand-workspace-overview
另外支持Azure Cosmos DB做HTAP
https://docs.microsoft.com/zh-cn/azure/cosmos-db/synapse-link
PPT
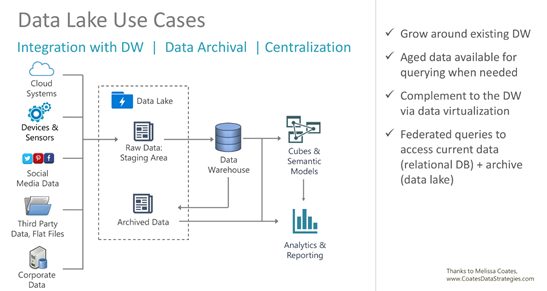
使用场景
- 数据湖探索 - 快速探索 Data Lake 中各种格式(Parquet、CSV、JSON)的数据。
- 逻辑数据仓库 – 基于原始数据提供关系抽象,而无需重新转换数据。
- 数据转换 - 使用 T-SQL 以简单、可缩放且高效的方式转换 Data Lake 中的数据,以便可将数据推送到 BI 和其他工具,存储到关系数据库。
用户角色
- 数据工程师: 转换和准备数据,简化ETL/ELT数据集成管道
- 数据科学家: 快速使用数据湖的内容做AI和机器学习
- 数据分析师: 使用熟悉的 T-SQL,Spark查询和分析数据
- BI专业人员: 快速基于数据湖中的数据创建 Power BI报表
用法
查询外部文件
Azure Data Lake在对象存储的基础上增加了文件层级目录结构,面向大数据分析优化。
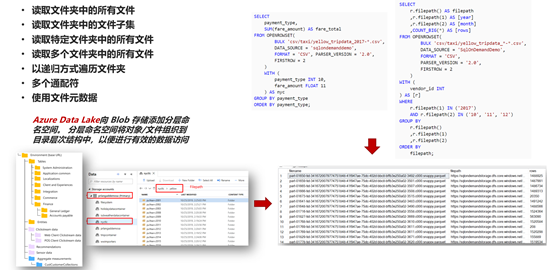
- 查询 CSV 文件
- 查询 Parquet 文件
- 查询 JSON 文件
- 查询 Parquet和JSON嵌套值
- 查询文件夹和多个 CSV 文件
- 在查询中使用文件元数据
https://docs.microsoft.com/zh-cn/azure/synapse-analytics/sql/query-data-storage
视图

外表

查询结果导出

复杂查询
/*分页查询*/select countries_and_territories, year, month, day, casesfrom openrowset( bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.parquet', format = 'parquet') as rowsorder by year, month, day OFFSET 30 ROWSFETCH NEXT 10 ROWS ONLY;/*字符组合*/select top 10 geo_id, year, month, cases = '{' + string_agg(concat('"',day,'":',cases), ',') within group (order by day asc) + '}'from openrowset( bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.parquet', format = 'parquet') as rowsgroup by geo_id, year, month;/*透视*/with cases as ( select countries_and_territories, year, month, day, cases from openrowset( bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.parquet', format = 'parquet') as rows)select top 10 *from casesPIVOT ( SUM (cases) FOR day IN ( [1], [2], [3], [4], [5], [6], [7]) ) AS months
/*逆透视*/with cases as ( select countries_and_territories, year, month, day, cases, deaths from openrowset( bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.parquet', format = 'parquet') as rows where continent_exp = 'Europe' and year = 2020)select top 100 countries_and_territories, year, month, day, property, valuefrom casesUNPIVOT ( value FOR property IN ( [cases], [deaths] ) ) AS unpivoted /*会话上下文*/CREATE OR ALTER VIEW casesAS SELECT * FROM openrowset( bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.parquet', format = 'parquet') as rows WHERE continent_exp = CAST(SESSION_CONTEXT(N'continent') AS VARCHAR(8000))exec sp_set_session_context 'continent', 'Europe';SELECT TOP 10 * FROM caseshttps://techcommunity.microsoft.com/t5/blogs/blogarticleprintpage/blog-id/AzureSynapseAnalyticsBlog/article-id/175
缺点
不支持缓存,不支持查询Azure SQL/PostgreSQL/SQL DW
//估计今年会支持这2大特性
Power BI组合
由于是按查询量计费,目前版本没有缓存,不适合高频查询。将数据全加载在Power BI内存模型,Power BI访问是按用户计费,可以无限查询访问,刚好解决此问题,定时刷新报告即可。还可利用Power BI的聚合表,复合模型特性功能。
聚合表

https://docs.microsoft.com/zh-cn/power-bi/transform-model/desktop-aggregations
复合模型

https://docs.microsoft.com/zh-cn/power-bi/connect-data/desktop-directquery-datasets-azure-analysis-services
Power BI本身可以直接查询Azure Data Lake,不需要通过Azure Synapse Analytics Serverless,两者的比较可以查看相关文章。
- 推荐使用Parquet,支持下压
- 直接查询Serverless没有速度优势
- 在有转换逻辑下有query folding情况下Serverless会更快
https://blog.crossjoin.co.uk/2021/01/24/comparing-the-performance-of-importing-data-into-power-bi-from-adlsgen2-direct-and-via-azure-synapse-analytics-serverless/
https://blog.crossjoin.co.uk/2021/01/31/comparing-the-performance-of-importing-data-into-power-bi-from-adlsgen2-direct-and-via-azure-synapse-analytics-serverless-part-2-transformations/
https://datamonkeysite.com/2021/01/07/pushdown-filters-in-synapse-serverless-from-powerbi/
另外Power BI已支持Parquet文件。

SSAS组合
SSAS模型中表的不同分区可以是不同数据源,做冷热分离。
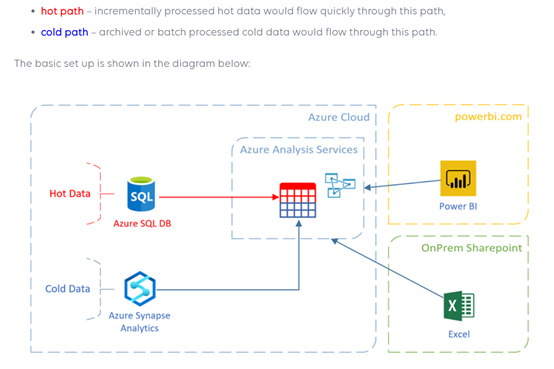
Azure SQL组合
有许多情况下,您可能需要从 Azure SQL 数据库访问放置在 Azure 数据湖上的外部数据,但Azure SQL目前不支持Polybase虚拟化查询外表(SQL Server可以)。可以通过Synapse Analytics Serverless间接实现。
/*Synapse中创建外表*/CREATE EXTERNAL TABLE csv.YellowTaxi ( pickup_datetime DATETIME2, dropoff_datetime DATETIME2, passenger_count INT, ...) WITH ( data_source= MyAdls, location = '/**/*.parquet', file_format = ParquetFormat);/*Azure SQL中建外部数据源*/CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'put some strong password here';GOCREATE DATABASE SCOPED CREDENTIAL SynapseSqlCredential WITH IDENTITY = '<synapse sql username>', SECRET = '<synapse sql password>'; GOCREATE EXTERNAL DATA SOURCE SynapseSqlDataSourceWITH ( TYPE = RDBMS, LOCATION = '<synapse workspace>-ondemand.sql.azuresynapse.net', DATABASE_NAME = 'SampleDB', CREDENTIAL = SynapseSqlCredential);GO/*Azure SQL中建Synapse外表*/CREATE SCHEMA csv;GOCREATE EXTERNAL TABLE csv.YellowTaxi( vendor_id VARCHAR(100) COLLATE Latin1_General_BIN2, pickup_datetime DATETIME2, dropoff_datetime DATETIME2, passenger_count INT, trip_distance FLOAT, rate_code INT, store_and_fwd_flag VARCHAR(100) COLLATE Latin1_General_BIN2, pickup_location_id INT, dropoff_location_id INT, payment_type INT, fare_amount FLOAT, extra FLOAT, mta_tax FLOAT, tip_amount FLOAT, tolls_amount FLOAT, improvement_surcharge FLOAT, total_amount FLOAT)WITH ( DATA_SOURCE = SynapseSqlDataSource );
https://devblogs.microsoft.com/azure-sql/read-azure-storage-files-using-synapse-sql-external-tables/
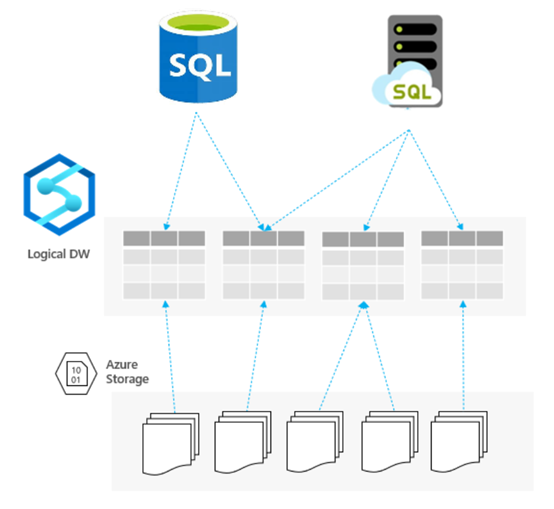
MPP始终会遇到数据倾斜问题,当前大部分关系数据库已经支持列存储,是否需要MPP数仓值得考虑。使用大数据Kimball模式,数据湖+数据集市。
Synapse Analytics Serverless+Azure SQL(列存储表)就是此模式。SQL Server 2019的列存储表已经非常完美。
- 对象存储或Hive做ODS层,归档区
- 关系数据库做数仓
学习材料
Azure Synapse Analytics默认开通服务器版本,不使用MPP SQL的情况下费用很低,推荐大家去体验下,下面连接是官方学习课程。
https://docs.microsoft.com/zh-cn/learn/paths/build-data-analytics-solutions-using-azure-synapse-serverless-sql-pools/
Data Mesh
同时还有另外一种数据概念,数据网格,由Thoughtworks提出。可以查看这篇博客文章
https://www.jamesserra.com/archive/2021/02/data-mesh/
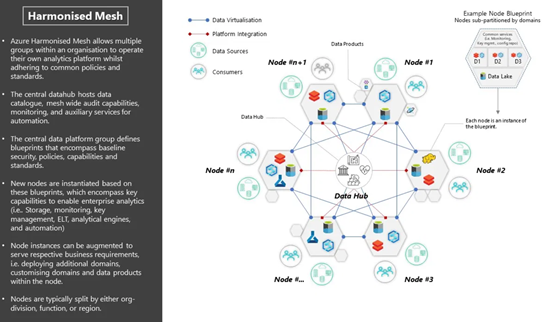
- Synapse serverless跨库查询Azure Data Lake
官方案例
https://azure.microsoft.com/zh-cn/blog/4-common-analytics-scenarios-to-build-business-agility/
原文转载:http://www.shaoqun.com/a/588613.html
vat:https://www.ikjzd.com/w/109
一淘网比价平台:https://www.ikjzd.com/w/1698
数据湖仓自从Databricks提出Lakehouse后,同时Snowflake的上市,湖仓一体成为数据领域最火热的话题。https://databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html核心的理念是DeltaLake使Hadoop有了ACID事务能力,使用Spark内存做实时,批,AI计算层。这样就可以用分布式文件存储颠覆关系
米谷:https://www.ikjzd.com/w/1788
二类电商:https://www.ikjzd.com/w/1457
达方物流:https://www.ikjzd.com/w/2562
亚马逊KYC是什么?哪些情况会触发KYC审核?:https://www.ikjzd.com/home/97516
不知道哪里找红人?亚马逊的官方渠道你试过没有?:https://www.ikjzd.com/home/103630
亚马逊无人便利店最早年底登陆英国/中国大陆直发订单仅接受Wish邮配送:https://www.ikjzd.com/home/8386
没有评论:
发表评论