高可靠性分析
Kafka的高可靠性的保障来源于其健壮的副本(replication)策略。通过调节其副本相关参数,可以使得Kafka在性能和可靠性之间运转的游刃有余。Kafka从0.8.x版本开始提供Partition级别的复制,replication数量可以配置文件(default.replication.refactor)中或者创建Topic的时候指定。
这里先从Kafka文件存储机制入手,从最底层了解Kafka的存储细节,进而对存储有个微观的认知。之后通过Kafka复制原理和同步方式来阐述宏观层面的概念。最后从ISR,HW,leader选举以及数据可靠性和持久性保证等等各个维度来丰富对Kafka相关知识点的认知。
Kafka文件存储机制
Kafka中消息是以Topic进行分类的,生产者通过Topic向Kafka Broker发送消息,消费者通过Topic读取数据。然而Topic在物理层面又能以Partition为分组,一个Topic可以分成若干个Partition,那么Topic以及Partition又是怎么存储的呢?Partition还可以细分为Segment,一个partition物理上由多个Segment组成,那么这些Segment又是什么呢?下面我们来一一揭晓。
为了便于说明问题,假设这里只有一个Kafka集群,且这个集群只有一个Kafka Broker,即只有一台物理机。在这个Kafka Broker中配置log.dirs=/tmp/Kafka-logs,以此来设置Kafka消息文件存储目录,与此同时创建一个名为topic_zzh_test的Topic,Partition的数量为4(kafka-topics.sh --create --zookeeper localhost:2181 --partitions 4 --topic topic_zzh_test --replication-factor 1)。那么我们此时在/tmp/Kafka-logs目录中可以看到生成了4个目录:
drwxr-xr-x 2 root root 4096 Apr 10 16:10 topic_vms_test-0drwxr-xr-x 2 root root 4096 Apr 10 16:10 topic_vms_test-1drwxr-xr-x 2 root root 4096 Apr 10 16:10 topic_vms_test-2drwxr-xr-x 2 root root 4096 Apr 10 16:10 topic_vms_test-3在Kafka文件存储中,同一个Topic下有多个不同的Partition,每个Partiton为一个目录,Partition的名称规则为:topic名称+有序序号,第一个序号从0开始计,最大的序号为Partition数量减1,Partition是实际物理上的概念,而Topic是逻辑上的概念。
上面提到Partition还可以细分为Segment,这个Segment又是什么?如果就以Partition为最小存储单位,我们可以想象当Kafka Producer不断发送消息,必然会引起Partition文件的无限扩张,这样对于消息文件的维护以及已经被消费的消息的清理带来严重的影响,所以这里以Segment为单位又将Partition细分。每个Partition(目录)相当于一个巨型文件被平均分配到多个大小相等的Segment(段)数据文件中(每个Segment文件中消息数量不一定相等)这种特性也方便Old Segment的删除,即方便已被消费的消息的清理,提高磁盘的利用率。每个Partition只需要支持顺序读写就行,Segment的文件生命周期由服务端配置参数(log.segment.bytes,log.roll.{ms,hours}等若干参数)决定。
Segment文件由两部分组成,分别为index文件和log文件,分别表示为Segment索引文件和数据文件。这两个文件的命令规则为:Partition全局的第一个segment从0开始,后续每个Segment文件名为上一个Segment文件最后一条消息的offset值,数值大小为64位,20位数字字符长度,没有数字用0填充,如下:
00000000000000000000.index00000000000000000000.log00000000000000170410.index00000000000000170410.log00000000000000239430.index00000000000000239430.log以上面的Segment文件为例,展示出Segment:00000000000000170410的index文件和log文件的对应的关系,如下图:
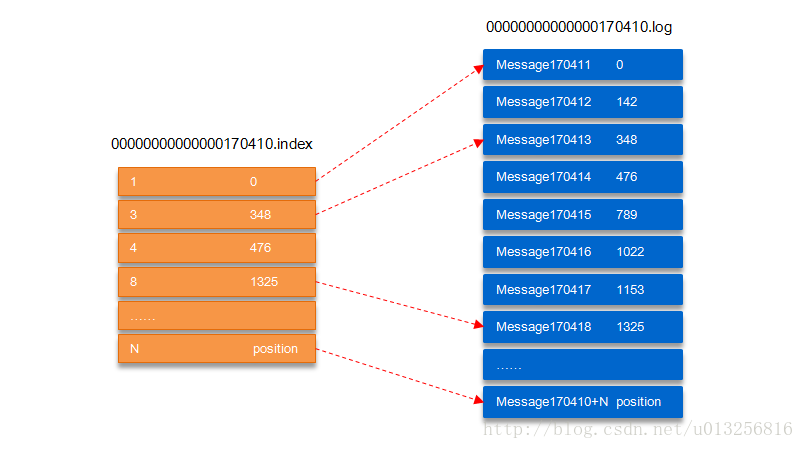
如上图,index索引文件存储大量的元数据,log数据文件存储大量的消息,索引文件中的元数据指向对应数据文件中message的物理偏移地址。
1. 如何根据索引文件元数据定位数据位置?如:index索引文件元数据[3,348],在log数据文件中表示第3个消息,在全局partition中表示170410+3=170413个消息,该条消息在相应log文件中的物理偏移地址为348。2. 那么如何从partition中通过offset查找message呢?如:读取offset=170418的消息,查找segment文件,其中,α. 00000000000000000000.index为最开始的文件,β. 00000000000000170410.index(start offset=170410+1=170411),γ. 00000000000000239430.index(start offset=239430+1=239431),因此,定位offset=170418在00000000000000170410.index索引文件中。其他后续文件可以依次类推,以偏移量命名并排列这些文件,然后根据二分查找法就可以快速定位到具体文件位置。其次,根据00000000000000170410.index文件中的[8,1325]定位到00000000000000170410.log文件中的1325的位置进行读取。3. 那么怎么知道何时读完本条消息,否则就读到下一条消息的内容了?因为消息都具有固定的物理结构,包括:offset(8 Bytes)、消息体的大小(4 Bytes)、crc32(4 Bytes)、magic(1 Byte)、attributes(1 Byte)、key length(4 Bytes)、key(K Bytes)、payload(N Bytes)等等字段,可以确定一条消息的大小,即读取到哪里截止。复制原理和同步方式
Kafka中Topic的每个Partition有一个预写式的日志文件,虽然Partition可以继续细分为若干个Segment文件,但是对于上层应用来说可以将Partition看成最小的存储单元(一个有多个Segment文件拼接的"巨型"文件),每个Partition都由一些列有序的、不可变的消息组成,这些消息被连续的追加到Partition中。

上图中有两个新名词:HW和LEO。这里先介绍下LEO,LogEndOffset的缩写,表示每个Partition的log最后一条Message的位置。HW是HighWatermark的缩写,是指Consumer能够看到的此Partition的位置,这个涉及到多副本的概念,这里先提及一下,下节再详表。
言归正传,为了提高消息的可靠性,Kafka每个Topic的Partition有N个副本(replicas),其中N(>=1)是Topic的复制因子(replica fator)的个数。Kafka通过多副本机制实现故障自动转移,当Kafka集群中一个Broker失效情况下仍然保证服务可用。在Kafka中发生复制时确保Partition的日志能有序地写到其他节点上,N个replicas中,其中一个replica为Leader,其他都为Follower, Leader处理Partition的所有写请求,与此同时,Follower会被动定期地去复制Leader上的数据。
如下图所示,Kafka集群中有4个Broker, 某Topic有3个Partition,且复制因子即副本个数也为3:
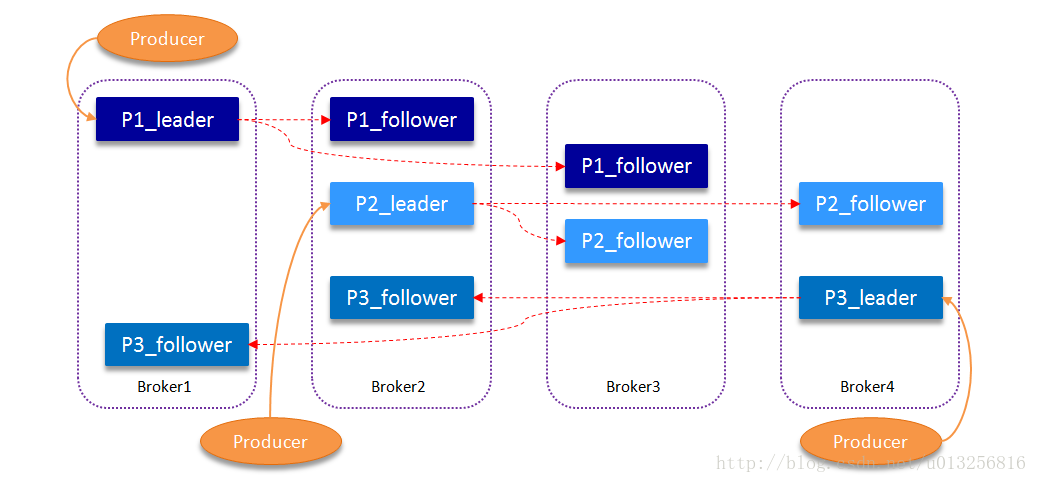
Kafka提供了数据复制算法保证,如果Leader发生故障或挂掉,将选举一个新Leader,并接受客户端消息的写入。Kafka确保从同步副本列表中选举一个副本为Leader,或者说Follower追赶Leader数据。Leader负责维护和跟踪ISR(In-Sync Replicas的缩写,即副本同步队列)中所有Follower滞后的状态。当Producer发送一条消息到Broker后,Leader写入消息并复制到所有Follower。消息提交之后才被成功复制到所有的同步副本。消息复制延迟受最慢的Follower限制,重要的是快速检测慢副本,如果Follower"落后"太多或者失效,leader将会把它从ISR中删除。
ISR
上节我们涉及到ISR (In-Sync Replicas),这个是指副本同步队列。副本数对Kafka的吞吐率是有一定的影响,但极大的增强了可用性。默认情况下,Kafka的replica数量为1,即每个Partition都有一个唯一的Leader,为了确保消息的可靠性,通常应用中将其值(由Broker的参数default.replication.factor指定)大小设置为大于1,比如3。 所有的副本(replicas)统称为Assigned Replicas,即AR。ISR是AR中的一个子集,由Leader维护ISR列表,Follower从Leader同步数据有一些延迟(包括延迟时间replica.lag.time.max.ms和延迟条数replica.lag.max.messages两个维度, 当前最新的版本0.10.x中只支持replica.lag.time.max.ms这个维度),任意一个超过阈值都会把Follower剔除出ISR, 存入OSR(Outof-Sync Replicas)列表,新加入的Follower也会先存放在OSR中。AR=ISR+OSR。
Kafka 0.9.0.0版本后移除了replica.lag.max.messages参数,只保留了replica.lag.time.max.ms作为ISR中副本管理的参数。为什么这样做呢?replica.lag.max.messages表示当前某个副本落后Leader的消息数量超过了这个参数的值,那么Leader就会把Follower从ISR中删除。假设设置replica.lag.max.messages=4,那么如果Producer一次传送至Broker的消息数量都小于4条时,因为在leader接受到Producer发送的消息之后,而follower副本开始拉取这些消息之前,follower落后leader的消息数不会超过4条消息,故此没有follower移出ISR,所以这时候replica.lag.max.message的设置似乎是合理的。但是Producer发起瞬时高峰流量,Producer一次发送的消息超过4条时,也就是超过replica.lag.max.messages,此时Follower都会被认为是与Feader副本不同步了,从而被踢出了ISR。但实际上这些Follower都是存活状态的且没有性能问题。那么在之后追上Leader,并被重新加入了ISR。于是就会出现它们不断地剔出ISR然后重新回归ISR,这无疑增加了无谓的性能损耗。而且这个参数是Broker全局的。设置太大了,影响真正"落后"Follower的移除;设置的太小了,导致Follower的频繁进出。无法给定一个合适的replica.lag.max.messages的值,故此,新版本的Kafka移除了这个参数。
注意:ISR中包括:Leader和Follower。
上面一节还涉及到一个概念,即HW。HW俗称高水位,HighWatermark的缩写,取一个Partition对应的ISR中最小的LEO作为HW,Consumer最多只能消费到HW所在的位置。另外每个replica都有HW,Leader和Follower各自负责更新自己的HW的状态。对于Leader新写入的消息,Consumer不能立刻消费,Leader会等待该消息被所有ISR中的replicas同步后更新HW,此时消息才能被Consumer消费。这样就保证了如果Leader所在的Broker失效,该消息仍然可以从新选举的Leader中获取。对于来自内部Broker的读取请求,没有HW的限制。
下图详细的说明了当Producer生产消息至Broker后,ISR以及HW和LEO的流转过程:
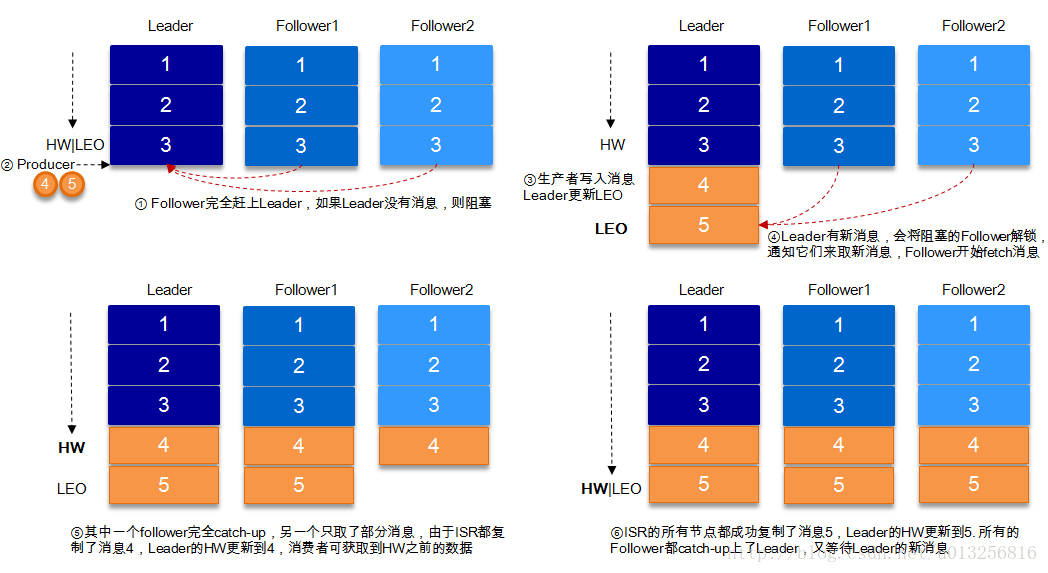
由此可见,Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的Follower都复制完,这条消息才会被commit,这种复制方式极大的影响了吞吐率。而异步复制方式下,Follower异步的从Leader复制数据,数据只要被Leader写入log就被认为已经commit,这种情况下如果follower都还没有复制完,落后于Leader时,突然Leader宕机,则会丢失数据。而Kafka的这种使用ISR的方式则很好的均衡了确保数据不丢失以及吞吐率。
Kafka的ISR的管理最终都会反馈到Zookeeper节点上。具体位置为:/brokers/topics/[topic]/partitions/[partition]/state。目前有两个地方会对这个Zookeeper的节点进行维护:
- Controller来维护:Kafka集群中的其中一个Broker会被选举为Controller,主要负责partition管理和副本状态管理,也会执行类似于重分配partition之类的管理任务。在符合某些特定条件下,Controller下的LeaderSelector会选举新的Leader,ISR和新的leader_epoch及controller_epoch写入Zookeeper的相关节点中。同时发起LeaderAndIsrRequest通知所有的replicas。
- Leader来维护:Leader有单独的线程定期检测ISR中Follower是否脱离ISR,如果发现ISR变化,则会将新的ISR的信息返回到Zookeeper的相关节点中。
欢迎关注,《大数据成神之路》系列文章
欢迎关注,《大数据成神之路》系列文章
欢迎关注,《大数据成神之路》系列文章
原文转载:http://www.shaoqun.com/a/512670.html
易佰:https://www.ikjzd.com/w/2023
stadium:https://www.ikjzd.com/w/2729
高可靠性分析Kafka的高可靠性的保障来源于其健壮的副本(replication)策略。通过调节其副本相关参数,可以使得Kafka在性能和可靠性之间运转的游刃有余。Kafka从0.8.x版本开始提供Partition级别的复制,replication数量可以配置文件(default.replication.refactor)中或者创建Topic的时候指定。这里先从Kafka文件存储机制入手,从最底
let go:let go
reverb:reverb
Shopee不要再去花冤枉钱去做广告站内引流小技巧!:Shopee不要再去花冤枉钱去做广告站内引流小技巧!
金秀莲花山杜鹃花游记?广西金秀莲花山怎么走?:金秀莲花山杜鹃花游记?广西金秀莲花山怎么走?
人人喊打!无耻亚马逊公然出售辱华&港独产品!:人人喊打!无耻亚马逊公然出售辱华&港独产品!
没有评论:
发表评论